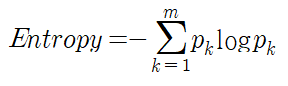AdaBoost는 순차적으로 여러 개의 약분류기(weak classifier)를 결합시켜 하나의 강분류기를 구성하는 알고리즘으로 1996년 Freund와 Schapire가 제안한 부스팅 기법이다. 초기에는 모든 샘플에 대하여 동일한 가중치를 주고 약분류기를 학습시킨 뒤, 이전 분류기에서 잘못 분류된 샘플의 가중치를 크게함으로써 강분류기를 만들어가는 알고리즘이다.
AdaBoost는 이진 분류(binary classification)에 최적화되어 있으며 학습자료가
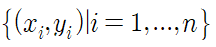
이고, 반응변수 y가
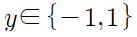
인 경우라고 하면, AdaBoost 알고리즘은 약분류기 f(x)들을 결합시켜 강분류기 F(x)를 마드는 과정이다.

여기서 α는 약분류기의 가중치인 최적계수이다.
구체적인 학습과정은 초기 샘플들의 가중치를

로 초기화 하고 가중치가 적용된 오류율 e를 구한다.

약분류기의 최적계수 α를 계산한다.

만약 무작위로 예측하여 오류율 e가 0.5에 가까워지면 (1-e)/e = 1이 되므로 약분류기의 가중치가 0에 가까워 지고, 오류율이 0.5보다 커지면 (1-e)/e < 1이 되어 약분류기의 가중치가 음수가 된다. 그 다음 모든 샘플의 부과하는 가중치를

로 수정한다. 그런 다음 가중치들의 합이 1이 되도록 정규화 한다. 이 과정을 m = 1,...,M 번 반복하게 되면 약분류기 f에 의하여 잘못 분류된 샘플의 가중치를 높이는 방식으로 조정되게 된다.
최종적으로 M단계 까지 적합된 강분류기 F(x)는
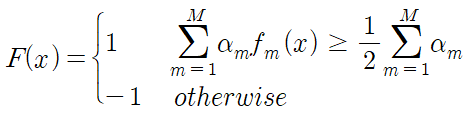
M개의 약분류기들의 선형결합으로 나타내어지며 다음 경계값 보다 큰 경우 1로 그렇지 않으면 -1로 분류하게 된다.
AdaBoost 적합 과정







'Machine Learning' 카테고리의 다른 글
| 지니지수(Gini index)를 이용한 최적 분류점 찾기 (0) | 2020.06.28 |
|---|---|
| Random Forest (0) | 2020.06.28 |